ドメイン適応の理論
本講義では、「ドメイン適応の理論」と題しまして、転移学習の基礎となる教師なしドメイン適応の理論解析について解説します。
前半ではドメイン間距離に基づいた期待リスクの上界について解説し、後半では不可能性定理と呼ばれる期待リスクの下界に関する結果を紹介します。
発表者: [発表者名]
所属: [所属]
日付: [日付]
目次
- 期待リスクと経験リスク
- 期待リスクの上界評価
- 期待リスクの下界評価
本講義では、転移学習における理論的枠組みとして、ドメイン適応における期待リスクの上界と下界について詳しく解説します。特に重要なのは、VC次元とラデマッハ複雑度の概念です。
期待リスクと経験リスク
転移学習での期待リスクの上界評価を紹介するために、まず単一ドメインで定義される基本的な概念について紹介します。本節の概念について、より詳しくは文献[361]などを参照してください。


図1: 期待リスクと経験リスクの概念
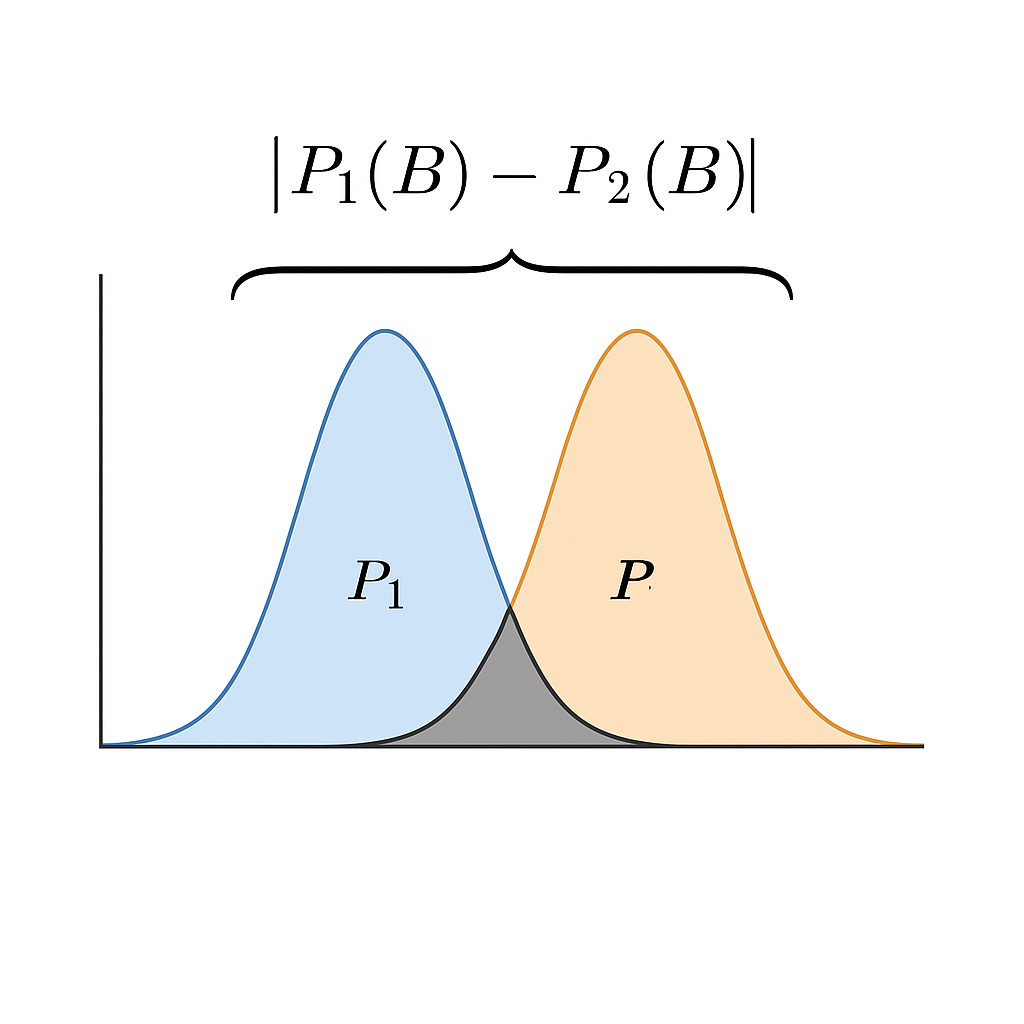
期待リスクは、モデルが未知のデータに対してどれだけの誤差を持つかを表す指標です。一方、経験リスクは観測できる訓練サンプル上での誤差です。転移学習の理論では、この二つのリスクの関係を解析することが重要となります。
転移学習では、元ドメインと目標ドメインの間の差異(ドメインシフト)が存在するため、従来の機械学習理論をそのまま適用できないことが問題となります。
定義と記法
入力はさまざまな形式をとりますが、本章では入力は実ベクトルで表されるとします。すなわち入力空間は $\mathcal{X} \subset \mathbb{R}^d$ を満たすと仮定します。また出力空間を集合 $\mathcal{Y}$ で表し、出力空間の元をラベルと呼びます。
- 入力空間: $\mathcal{X} \subset \mathbb{R}^d$
- 出力空間: $\mathcal{Y}$(分類問題では有限集合または連続集合)
- $P$ は直積空間 $\mathcal{X} \times \mathcal{Y}$ 上の同時分布を表す
- 自然数 $m \in \mathbb{N}$ に対し、$(\mathcal{X} \times \mathcal{Y})^m$ 上のサイズ $m$ の独立同一分布を $P^m$ と表す
- 観測値 $D = \{(x_i, y_i)\}_{i=1}^m \sim P^m$ を訓練サンプルと呼ぶ
- テストサンプルも訓練サンプルと独立同一な分布から得られると仮定
出力空間がさまざまな形式をとりえますが、ここでは出力空間が二つの元からなる場合を2値分類、三つ以上の元からなる場合を多値分類と呼びます。
損失関数 $\ell : \mathcal{Y} \times \mathcal{Y} \rightarrow \mathbb{R}_{\geq 0}$ を考えます。これは、分布 $P$ から得られたサンプル $(x, y)$ に対して、仮説 $h$ の予測がどの程度の誤差を持つかを損失関数 $\ell (y, h(x))$ によって測ります。
転移学習の基礎
転移学習では、入力空間 $\mathcal{X}$ から出力空間 $\mathcal{Y}$ への関数全体からなる集合を $\mathcal{F}(\mathcal{X}, \mathcal{Y})$ と表します。また、$\mathcal{F}(\mathcal{X}, \mathcal{Y})$ の部分集合 $\mathcal{H}=\{h : \mathcal{X} \rightarrow \mathcal{Y}\}$ を仮説集合と呼びます。
仮説に望むことは、訓練サンプルに対して誤差を小さくすることではなく、テストサンプルに対して誤差を小さくすることです。仮説の性能を適切に測るために、ある確率分布 $P$ に対して仮説 $h$ の予測の平均的な誤差は定義1.1における期待リスクとして定義されるのでした。
定義からわかるように、期待リスクは全空間 $\mathcal{X} \times \mathcal{Y}$ 上の期待値になっています。したがって、それは $P$ から得ることができるが、観測していないサンプルに対する誤差についても考慮に入れています。
最適仮説(optimal hypothesis)を、期待リスクを最小化するものと定めます。実際には真の分布 $P$ は未知なので、与えられた仮説に対して期待リスクの計算は不可能であり、最適仮説を直接求めることはできません。
VC次元による上界
仮説空間の複雑度を定量化するための代表的な方法として、ここではVC次元について紹介します。
2値分類の問題に対し、与えられた仮説集合 $\mathcal{H}$ の VC次元(Vapnik-Chervonenkis dimension)VC($\mathcal{H}$)は、有限部分集合 $\mathcal{X}' \subset \mathcal{X}$ が存在し、$\mathcal{X}'$ 上の任意のラベル付けに対し、ある仮説 $h \in \mathcal{H}$ が存在し、$\mathcal{X}'$ の元のラベルをすべて正しく分類できる場合の、$\mathcal{X}'$ の要素数の最大値を表します。これを数学的に表現すると以下の形になります: $$VC(\mathcal{H}) = \max \left\{ k \in \mathbb{N} \middle| \begin{array}{c} \exists \mathcal{X}' = \{x_1,...,x_k\} \subset \mathcal{X}, \forall y \in \{\pm1\}^k, \\ \exists h \in \mathcal{H}, \forall i \in \{1,...,k\}; h(x_i) = y_i \end{array} \right\}$$
VC次元は有限になるとは限らないことに注意してください。特に、仮説集合を定義するためのパラメータ数は有限であるにも関わらず、その仮説集合のVC次元は無限になる場合があります[241, 1.2.1節]。
$\mathcal{X}$ を入力空間、$\mathcal{Y} = \{\pm1\}$ を出力空間、$P$ を同時分布とします。$\mathcal{D}$ を $P$ から独立同一に得られたサイズ $m$ のサンプルとし、仮説集合 $\mathcal{H} = \{h : \mathcal{X} \rightarrow \mathcal{Y}\}$ の VC 次元を VC($\mathcal{H}$) とします。$m \geq$ VC($\mathcal{H}$) のとき、任意の $\delta \in (0, 1]$ に対し、少なくとも $1 - \delta$ の確率で以下が成り立ちます: $$\sup_{h \in \mathcal{H}} |\hat{R}_m(h) - R(h)| \leq 2 \sqrt{\frac{VC(\mathcal{H})}{m} \ln \frac{em}{VC(\mathcal{H})}} + \sqrt{\frac{\ln(2/\delta)}{2m}}$$ ここで $e$ はネイピア数を表します。
VC次元による上界の含意
上記の定理の帰結として、任意の仮説 $h \in \mathcal{H}$ と任意の $\delta \in (0, 1]$ に対し、少なくとも $1 - \delta$ の確率で以下が成り立ちます:
左辺は期待リスクなので、未知の分布に依存しており原理的に計算できません。一方で、仮説集合は既知なので、原理的にはVC次元VC($\mathcal{H}$)も既知と仮定でき、したがって不等式の右辺は計算できます。これより、経験リスクとVC次元から未知の期待リスクの大きさが評価可能であることが明らかになりました。
また定理3.2は、サンプル数が増加するとき、経験リスクの期待リスクへの収束速度がVC次元の小ささに応じて早まることも示しています。
VC次元の有限性は経験リスクが期待リスクへ一様に収束することを保証しています。しかし一方で、実際にはVC次元に基づいた上界はさまざまな不都合を抱えています:
1. 多くの場合は仮説集合に対してそのVC次元を具体的に計算するのは困難
2. VC次元は無限の値をとることがあり、その場合には上界は意味をなさない
3. VC次元はアルゴリズムやサンプルの従う確率分布の情報を考慮に入れていない
ラデマッハ複雑度
次にVC次元のいくつかの問題を解決するために、仮説空間の複雑度の指標としてラデマッハ複雑度と呼ばれる量を導入します。確率1/2で1、確率1/2で−1の値をとる2値確率変数をラデマッハ変数と呼びます。このラデマッハ変数を用いてラデマッハ複雑度は以下のように定義されます。
$\mathcal{X}$ 上の確率分布 $P$ から得られたラベルなしサンプル $\mathcal{D} = \{x_i\}_{i=1}^m$ と仮説集合 $\mathcal{H}$ に対し、経験ラデマッハ複雑度 (empirical Rademacher complexity) は以下で定義されます: $$\hat{\mathfrak{R}}_m(\mathcal{H}) = \mathbb{E}_{\kappa=(\kappa_1,...,\kappa_m)} \left[ \sup_{h \in \mathcal{H}} \frac{2}{m} \sum_{i=1}^m \kappa_i h(x_i) \right]$$ ここで $\kappa$ は $m$ 個の独立なラデマッハ変数を表します。仮説集合に対する(期待)ラデマッハ複雑度 (expected Rademacher complexity) は経験ラデマッハ複雑度の期待値として定義されます: $$\mathfrak{R}_m(\mathcal{H}) = \mathbb{E}_{\mathcal{D} \sim P^m} [\hat{\mathfrak{R}}_m(\mathcal{H})]$$
ラデマッハ変数 $\kappa_i$ はサンプル $x_i$ に対する一様ランダムなラベル付けを行った状況と解釈できます。したがって経験ラデマッハ複雑度は、ラベルなしサンプルを固定した場合に、仮説集合がラデマッハ変数で表されるラベル付けにどの程度適応できるかを測っているとみなすことができます。
ラデマッハ複雑度の特徴
ラデマッハ複雑度はVC次元とは異なる状況での複雑度を定義しています。すなわち、ラデマッハ複雑度はラベル付けがランダムな場合に仮説集合の表現能力を測っています。一方で、VC次元はラベル付けが仮説集合にとって最も対応しにくい場合に、仮説集合の表現能力を測っているとみなすことができます。
またラデマッハ複雑度はVC次元とは異なり、ラベルなしサンプルが従う確率分布の情報を用いて定義されています。
以下の定理は経験および期待ラデマッハ複雑度に基づいた期待リスクの上界を与えています[28, 162]。
$\mathcal{D} = \{(x_i, y_i)\}_{i=1}^m$ を確率分布 $P$ から独立同一に得られたサイズ $m$ のサンプルとし、$\mathcal{H} \subset \{h : \mathcal{X} \rightarrow \mathcal{Y}\}$ を仮説集合とします。そのとき任意の $\delta \in (0, 1]$ と任意の仮説 $h \in \mathcal{H}$ に対し、少なくとも確率 $1 - \delta$ で以下が成り立ちます: $$R(h) \leq \hat{R}_m(h) + \mathfrak{R}_m(\mathcal{H}) + \sqrt{\frac{\ln \frac{1}{\delta}}{2m}},$$ $$R(h) \leq \hat{R}_m(h) + \hat{\mathfrak{R}}_m(\mathcal{H}) + 3\sqrt{\frac{\ln \frac{2}{\delta}}{2m}}$$
ラデマッハ複雑度とVC次元の関係
特に定理の後半の不等式は経験ラデマッハ複雑度を用いており、VC次元の場合とは異なりサンプル $\mathcal{D}$ に依存した形になっています。ラデマッハ複雑度を用いた上界は、サンプル依存上界(sample-dependent bound)と呼ばれるものの例になっています。
ラデマッハ複雑度はVC次元の定義とは異なった形をしている一方で、その二つは以下の不等式を用いて関連付けることができます[241]:
この結果はラデマッハ複雑度を用いた上界とVC次元を用いた上界を密接に結びつけています。